Integrating Sanity.io and Algolia
3 steps for synchronizing your content across both systems
You can watch the video version of this guide here
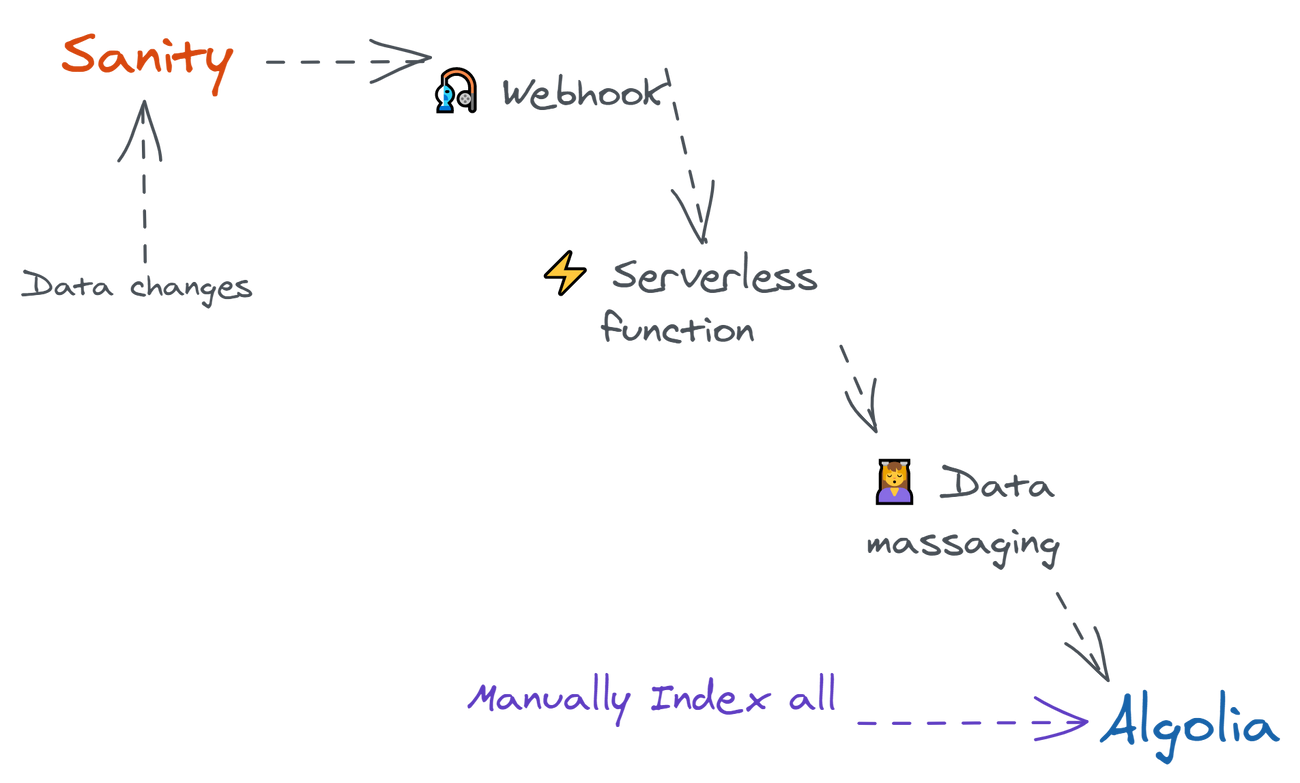
Before using Algolia to search through our Sanity.io data, we first need to sync content between the two systems. This guide will help you with that.
There are 3 main parts to this equation:
- Defining & querying the data we want to have in Algolia
- Indexing all existing Sanity content, which we can do any time there's a significant schema change
- Synchronizing changes between them - happens through Sanity webhooks fired on create, delete & update operations
I won't get into why connect Sanity & Algolia - I'm assuming you're already sold and here to see the technical implementation details. Let me know on Twitter if I should cover that!
Defining our search objects' data structure
The bigger our Algolia records are, the slower search requests will be. The hard limit is 10kb, but we want to keep them under 2kb for snappy response times. Hence, we don't want to index our entire Sanity documents.
To think about the data you want to index, I make 5 informal distinctions between fields:
- Bureaucratic/required fields are those you have to include no matter what
- objectID for updating records - usually the Sanity document's
_id - document's
_type - the revision ID (
_rev) as a just-in-case for special sync operations
- objectID for updating records - usually the Sanity document's
- Fields for textual search - think titles, descriptions, headings, etc.
- Data for faceting/categorization - tags, status, authors, genre, etc.
- Custom ranking factors - upvote count, date published, featured...
- These values need to be booleans (true/false) or numbers.
- In my GROQ query below, you'll notice I transformed
status(a string/enum) intostatusNumber.
- Presentational content you need for rendering results to users - images, visual properties, etc.
To experiment with these, I recommend creating and testing GROQ queries. We'll use the projections later on, so it's worth the investment. Here's a commented example from the recipes website I'm creating:
*[ _type == 'recipe' && !(_id in path('drafts.**')) && defined(slug.current) && status != 'unapproved' ] { // Bureaucracies _type, _rev, "objectID": _id, _createdAt, // Textual search title, description, "ingredients": ingredients[_type == "recipe.ingredient"].title, "headings": pt::text(body[ _type == "block" && style in ["h1", "h2", "h3", "h4"] ]), // Faceting duration, "categories": categories[]->{ title, _id, }, "tags": tags[]->{ title, _id, }, // Finer ranking "statusNumber": select( status == "approved" => 100, status == "pendingReview" => 50, -100 ), // Presentational content "mainImage": photos[0], }
If something in the query above is unclear, I wrote an in-depth guide on GROQ you may find useful 😉
After you run the query and make sure it's getting exactly the data you want, I recommend saving a subset of documents in a JSON file and manually uploading them to Algolia's dashboard to live test your search.
If you're indexing multiple document types, I'd recommend using the same GROQ query for all of them and running conditionals based on their type. It'd make the processes below easier to reason about. Here's an example:
*[ _type in ['recipe', 'article', 'user'] && !(_id in path('drafts.**')) && defined(coalesce(handle.current, slug.current)) ] { // Bureaucracies - shared across all _type, _rev, "objectID": _id, _createdAt, _type != "user" => { title, description, }, _type == "user" => { name, bio, }, _type == "recipe" => { "ingredients": ingredients[_type == "recipe.ingredient"].title, }, // ... }
Be sure to clear the index once you're done before moving to the next step. Else it'll be hard to see the effects of the programmatic insertions we'll do below.
Index all applicable documents
After you figure out the data structure & queries you need to run, indexing all is the simpler part. In short, we'll get the data and use Algolia's SDK to run saveObjects on it. Here's my code, in the shape of a SvelteKit API endpoint:
import sanityServerClient from '$lib/utils/sanityServerClient' import algoliasearch from 'algoliasearch' export const algoliaInstance = algoliasearch( process.env['ALGOLIA_APPLICATION_ID'], process.env['ALGOLIA_ADMIN_KEY'], ) const QUERY = `YOUR_QUERY_HERE` export const get = async (request) => { // Basic security to prevent others from hitting this API const passphrase = request.query.get('passphrase') if (passphrase !== process.env['ALGOLIA_SECRET']) { return { status: 401, } } const documents = await sanityServerClient.fetch(QUERY) const index = algoliaInstance.initIndex(process.env['ALGOLIA_INDEX']) try { console.time(`Saving ${documents.length} documents to index:`) await index.saveObjects(documents) console.timeEnd(`Saving ${documents.length} documents to index:`) return { status: 200, body: 'Success!', } } catch (error) { console.error(error) return { status: 500, body: error, } } }
If this script is successful running, you should see your data once you refresh the Algolia dashboard 🎉🎉
I use a serverless endpoint because I want to be able to flush all data even when I'm on the move. You can of course create a local script only you have access to - it's definitely safer from abuse.
Syncing data via webhooks
To make sure data is updated, deleted or created accordingly, we'll need to create an endpoint for handling Sanity's webhooks. These fire whenever there's a change in your dataset, sending a payload similar with the _ids of documents updated, created or deleted. Something similar to this:
{ "ids": { "updated": [], "created": ["M9IWNQzEM85EAsYtvAZnPd"], "deleted": [] } }
We could manually query these _ids, figure out their _type, get the appropriate data and send that to Algolia. Thankfully, though, we can delegate this grunt work to the official sanity-algolia package.
Here's how my serverless function for handling those webhooks looks like:
import sanityServerClient from '$lib/utils/sanityServerClient' import indexer from 'sanity-algolia' import { algoliaInstance, RECIPE_PROJECTION } from './index-all' export const post: RequestHandler = async (request) => { const passphrase = request.query.get('passphrase') if (passphrase !== process.env['ALGOLIA_SECRET']) { return { status: 401, } } const index = algoliaInstance.initIndex(process.env['ALGOLIA_INDEX']) const sanityAlgolia = indexer( { recipe: { index, // The projection is the piece of the GROQ query // where we determine what data to fetch projection: RECIPE_PROJECTION, }, // 💡 Could have many other document types here! }, // Serializer function for manipulating documents with Javascript // I'm not using it as GROQ is doing all the work (document) => document, // Visibility function to determine which document should be included (document) => !['unapproved'].includes(document.status), ) // Now let sanityAlgolia do the heavy lifting return sanityAlgolia .webhookSync(sanityServerClient, request.body as any) .then(() => ({ status: 200, body: 'Success!', })) .catch(() => ({ status: 500, body: 'Something went wrong', })) }
To test this is working, we can manually create a webhook payload and send that to the serverless function. For example, let's pick up the first object in Algolia and try to delete it by sending a request similar to this:
fetch(WEBHOOK_ENDPOINT, { method: "POST", headers: { "Content-Type": "application/json", }, body: JSON.stringify({ ids: { updated: [], created: [], // Add your document _id below: deleted: ["M9IWNQzEM85EAsYtvAZnPd"], }, }), });
If you got a 200 out of that, open the Algolia dashboard, wait a few seconds and refresh it to see if the document is gone. Otherwise, triple-check your credentials & index, and read through sanity-algolia's docs.
If the experiment above is successful, it means you're ready for production! Send your endpoint live, add its URL to Sanity's manage dashboard as a webhook for your project & you're good to go 🎉
This integration can definitely go deeper than this. My first implementation involved synchronizing almost 20 document types across 2 different Sanity datasets, with all sorts of data normalization challenges. I hope this guide gives a solid understanding that you can use when tackling these more complex use-cases. If not, feel free to reach out at meet@hdoro.dev or hdorodev!
I may eventually write about the search UI I'm building with Xstate and Svelte, with a strong focus on SEO, performance & UX. Glad to hear if that's of interest to you 😊